随着应用的不断迭代,场景的渲染开始越来越卡,数据量稍微大一点就卡顿明显,十分影响用户体验,记录一次场景性能优化过程,渲染时间从 200ms 下降到 20ms,效果明显。
问题描述
从产品给的反馈,将当前卡顿问题分类为如下三种情形
- 首次渲染时:首次加载方案并渲染时
- 正常渲染时:方案渲染完成后,缩放或平移时卡顿
- 交互渲染时:主要表现在框选对象时
- 数据更新时:框选大面积物体,进行批量更新时
本次重点关注首次渲染和正常渲染卡顿问题,交互渲染卡顿优先级比数据更高,数据更新卡顿问题的 ROI 较低,优先级最低。
问题定位
测试案例单层约有 2700 个车位,16 个塔楼,通过 chrome 开发者 Performance 工具进行 profiling 分析。
首次渲染
从 profiling 的结果来看
- Plan 421ms:其中 cleanup 42ms, Slot 245ms, Column 55ms, loadPlan 40ms, event setup 20ms
- layerVisible 12ms
渲染方案耗时总结
- cleanup 也比较耗时,可以做成一个空闲时任务
- event 和 visible 设置耗时主要花在对象查找上,看是否可以优化
- loadPlan 主要是索引重建和 slot geometry 计算
- Slots 解析过程主要是三维对象的创建,后面详细分析
关于对象查找的优化,发现对象查找耗时竟然这么久,一开始觉得很困惑,为啥会这么慢,比如查找某个 group
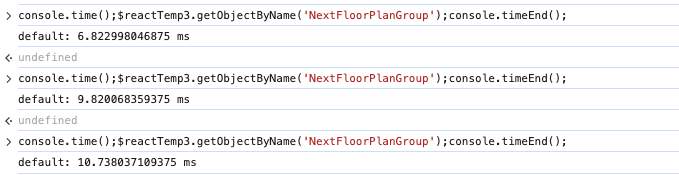
原因是 three.js scene 对象查找走的深度优先遍历,加上 NextFloorPlanGroup 在比较靠后的位置,所以特别慢,于是手动新增一个广度优先的遍历方式,优化后 event setup+visible control 总体耗时变化 32ms->2ms。
再分析一下 loadPlan 的耗时,索引重建感觉优化空间不大了,倒是 slot 需要进行变换以计算最终坐标,原变换过程是对每个点进行旋转+平移两步操作,于是尝试使用将旋转+平移合并成一个矩阵变换,优化后耗时变化 40ms->22ms。
最后重点分析一下 slots 创建耗时(column 本质上是 slot 的简化版,跳过)
- 完整 slots 178ms
- 移除 mesh 143ms
- 移除 edges 107ms
- 移除 polygon compute 146ms
本以为是车位轮廓坐标计算导致,但测试后发现影响并不大,换成模版+变换的形式,耗时也差不多。
关于解析 slots 中,除了关闭 edges 创建渲染,其他步骤提速均不明显,仔细查看 edges 步骤感觉也无从下手了。似乎创建这么多个 polygon 就是要这么长时间,尝试创建 polygon 时复用一个公共 Material,以避免创建那么多对象,结果耗时几乎没差别。
只是发现创建 slots 的过程中,会频繁触发 GC,每次 GC 都耗时 1-2ms,有待研究。

正常渲染时
具体性能指标如下:
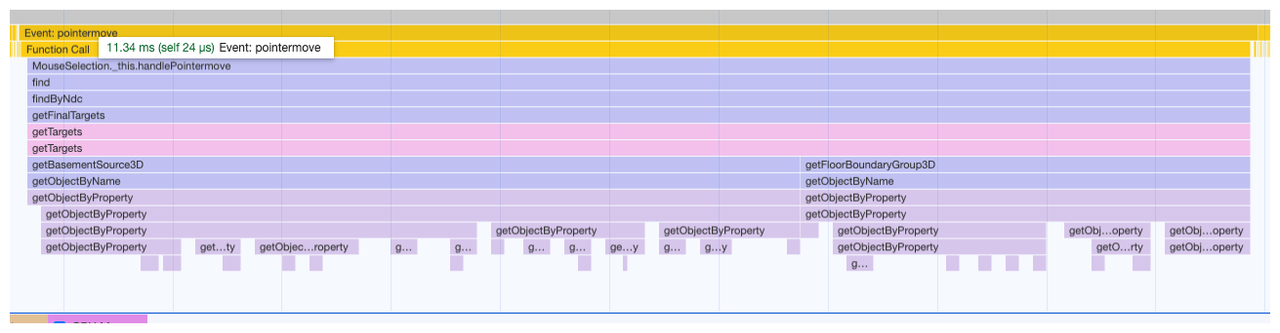
观察缩放平移时,会不断进行对象查找,耗时在 10-30ms 不等,但其实此时计算是没有必要的,可以优化一下。
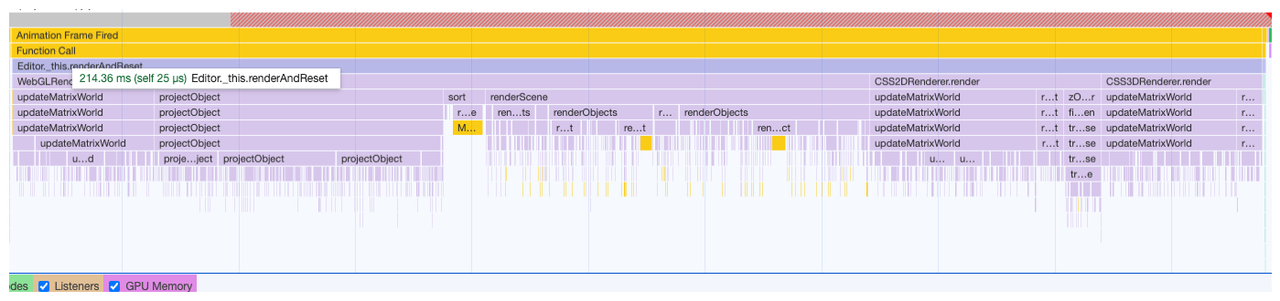
具体 render 耗时统计

当三个 render 同时使用时,其实 scene/camera 的矩阵没必要重复更新
- 查看源码发现其内部有做性能优化,会通过 matrixWorldNeedsUpdate 拦截掉重复的更新
- 那为什么还会慢呢,是数量太大循环导致的?还是 updateMatrix 导致的呢?答案是矩阵更新导致
- 关闭 matrixAutoUpdate 变得巨快,发现场景渲染为空,原因是 camera 的矩阵更新需要开启
如果选择直接关闭 matrix 自动更新,则 CSS3DRenderer 和 CSS2DRenderer 可以保持不变,否则需要想办法关闭 CSS3DRenderer/CSS2DRenderer 关于 scene/camera 的矩阵更新,提升会很大,目前并没有直接的 API 供使用。在 github 提针对 CSS3DRenderer/CSS2DRenderer 关闭更新特性的 PR 被拒,告知可以选择关闭更新,然后自行在 render 函数中手动更新。
矩阵更新性能测试 gl.render 执行时间
- 关闭matrixAutoUpdate 70ms-100ms
- 关闭matrixWorldAutoUpdate 60ms-80ms
- 全部关闭 50ms-80ms
数据不一定准确,体验下来就是关闭 matrixWorldAutoUpdate 比 matrixAutoUpdate 提速更明显一点。但全部关闭后 gl.render 大概能稳定在 60ms 左右,相比最初的 134ms,已经提升一倍多。
同时观察到一个现象,如果仅 render source 速度是飞快的,一旦加入 plan 后性能下降明显,因此统计一下是 plan 哪个数据导致性能急剧下降。
为了让感受更直观,保持 matrixAutoUpdate 默认开启状态下测试。

Note:其中设置 visible 为 false 逻辑中,updateWorldMatrix 时间不会减少,但 projectObject 和 renderScene 的时间会显著减少
做完如下优化后
- 镜头交互过程中不做对象选取
- 关闭 css2d/css3d renderer 的 matrix update
- 优化 polygon:尽可能使用 merge、simple line,同时全透明 mesh 设置 visible 为 false
此时性能指标如下,此时每次渲染时间稳定在了 40-60ms 之间(214ms->50ms),但观察发现超过 50ms 时 task 会被 chrome 标记为长任务,依旧存在部分长任务。
有没有办法可以继续优化,使得整体渲染稳定维持在 30ms 左右呢。
- 避免无效步骤:从 profile 结果来看,已经都是必须步骤了,除非彻底关闭 matrix auto update,但这会导致日常开发需要很小心,但确定不会修改的静态对象,可以选择手动关闭 matrix 更新
- 减少渲染对象
- 产品侧移除某些效果
- 技术侧尽可能 merge/instance 等方式合并/复用对象,但会存在两个问题,第一目前产品的编辑对象均可自由编辑,复用难度大,且大规模的合并/复用,需要重构现有的选取逻辑,工作量大,影响面广
- 减少数据量:如减少顶点数
- 提升关键部分计算性能
走到这一步时,突然想起用一下 scene.overrideMaterial 属性,发现前后性能没有差别,可见性能瓶颈主要还是卡在 CPU 上。
对象选取时
具体性能指标-包含选择
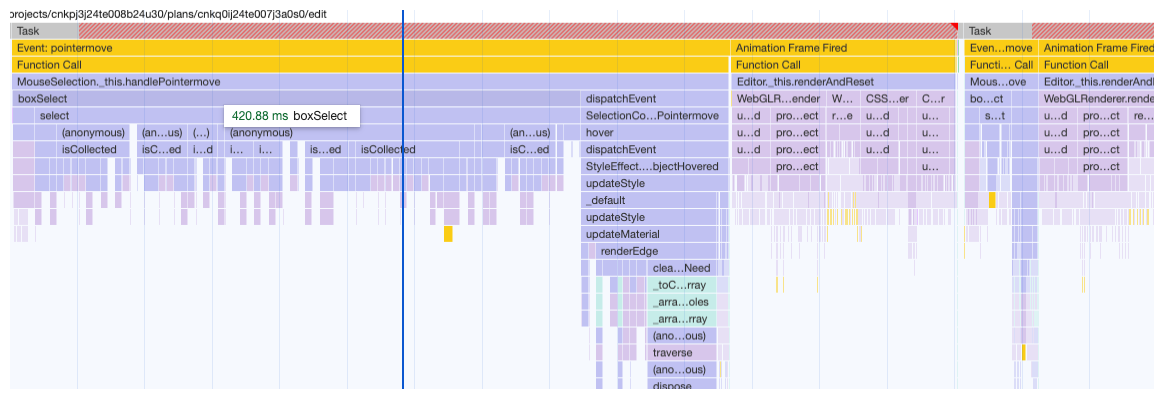
具体性能指标-交叉选择
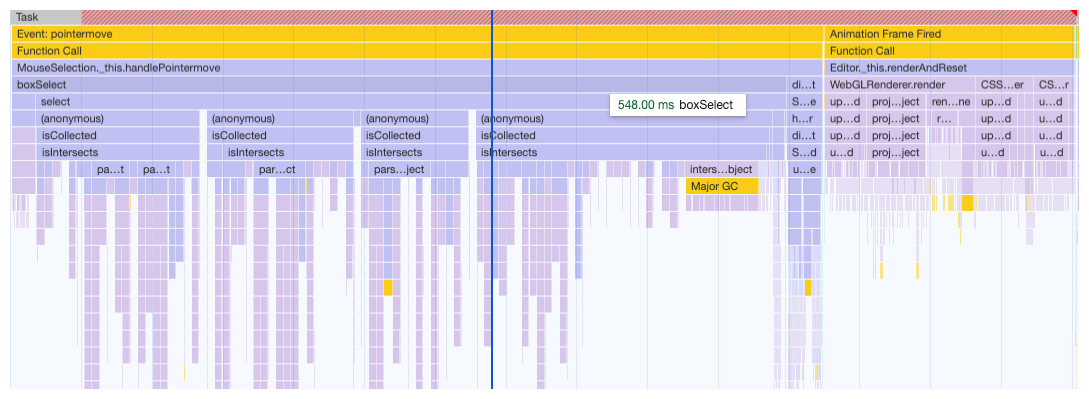
以上观察到当选择量增多时,box select 性能急剧下降。详细审查后发现,最大的瓶颈不在于计算框选对象,而是样式修改。
由于当前对于 Polygon 线条的样式修改,采用简单粗暴的方式,直接新建新的 edges 的方式,成本很高,于是改为修改 materials 的方式,修改后结果如下。

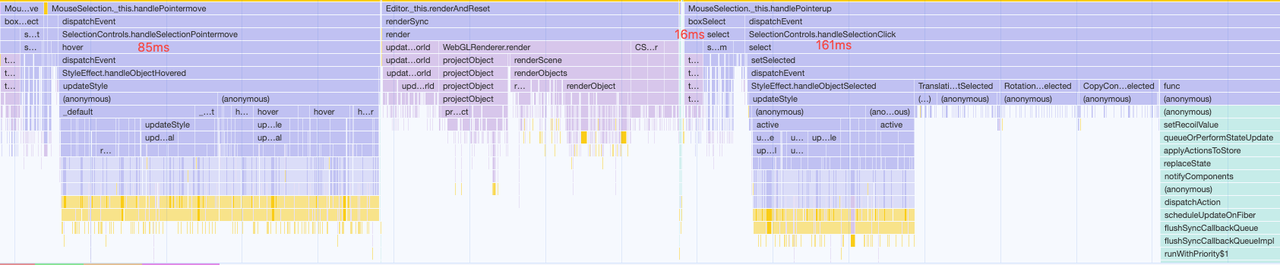
hover 和 select 性能均有很大提升,但为啥 select 比 hover 耗时长这么多呢。原因是因为
- 当确定对象选择时,平移/旋转/复制控件部分逻辑会被调用,主要做一些准备工作。选择将其优化成真正开始启用功能时再进行准备工作,直接减少 60ms 耗时
- 右侧渲染当前选中物体的信息面板

右侧具体耗时花费在 Slot 组件上,主要原因是从框选的车位 id 集合中,再去 floorPlans.slots 中找到完整数据的查找过程耗时,因为是 O(n^2) 的复杂度,转成 O(n) + memo 后,32ms->1.5ms,柱子同样优化后 5ms->0.5ms。

任务分片:框选相对比较耗时,但更严重的是任务的拥挤,光标移动过程中,会不断触发查找,会出现上一个还没处理完下一个就来的情况,从而导致触发越多越来越卡。任务分片的好处是过期的未完成的任务可以丢弃,且通常不会卡住主线程,缺点就是响应变成异步了,不是所见立即得。
总结
日后开发注意事项
- 一切以 profile 结果为主,不要去猜,重点关注非必要步骤、重复步骤、警惕 O(n^2) 的复杂度。
- 警惕对象查找的耗时,根据情况选择广度遍历还是深度遍历。
- 场景渲染优化的关键还是减少 draw calls 次数,大量小的对象是造成性能下降的元凶。
- 经过反复测试后,FatPolyline3D 性能不如 Polyline3D,如非必要,选 Polyline3D。
- 某些特殊情况,需要设置全透明对象,此时可以将 visible 设置为 false,此时并不影响选取,但能提升性能。
- 全局关闭 matrix auto update,但建议仅作为保留手段,除非你通过 profile 后发现花费了大量时间,且其他优化手段都用了之后,因为这会带来开发的不便利。但是局部手动关闭还是可考虑的,如静态对象,以及当父元素才是可操作单元,此时子元素关闭 matrixAutoUpdate 是安全的,注意不包括matrixWorldAutoUpdate
- 任务分片,避免卡住主线程
Next
- 如果 slot 和 column 可以明确几种规格,而不是用户自由发挥,此时可考虑使用 instanced mesh
- 对框选使用空间索引 quadtree
Event
部署到线上 dev 时,发现线上比本地要慢(50ms ->110ms),但同事电脑是好的。
很是费解,尝试将 chrome 版本升级后(v121->v123),线上直接起飞,甚至比之前的本地还要快 50ms->20ms。