关于 monorepo 这个话题其实已经探讨过多次,之前公司业务线扩充后,进行前端技术选型改造,考虑到之前单个 repo 代码量过大,编译部署巨慢的痛苦,索性就发展成了 multi-repo 的方式,每个业务线维护好自己的 repo,然后通过简单的微服务实现服务之间的连通,但与此而来新的问题也就出现了,因此希望寄托 monorepo 的方式解决掉开发和管理上的痛点。
multi-repo
没有绝对的劣势,先谈下 multi-repo 的优势
- 代码物理隔离,各个团队管理好自己的 repo 即可,仓库体积小,模块划分清晰
- 更好的伸缩性:小仓库可以更好的被管理,更少的合并地狱,团队不需要与其他团队协调,从而更快地执行
- 独立部署,提高单个服务的构建速度(相对传统的 single-repo 方案)
使用 multi-repo 模式,时间一长,最先摆在我们面前的问题就是,多项目之间如何共享代码,常用方式有
- Git Submodule
- Git Subtree
- NPM Pkg
这几种方式,都有各自的问题,比如 NPM 侧重于包的依赖管理,但没办法双向同步,更适用于子项目比较稳定的情形。Git Submodule 和 Git Subtree 都是官方支持的功能,但不具有依赖管理的功能
共享代码只是一个导火索,multi-repo 还带来了更多深层次的问题(其实很多问题在我们团队已经暴露出来,而且变得很尖锐)
- 代码分散在不同的 repo 中,容易导致大量重复的内容,且团队间不容易迭代同步
- dependencies 依赖被大量重复安装(忘记被 node_modules 支配的恐惧了吗)
- configuration
- environments
- build configurations
- test configuration
- eslint
- prettier
- pull request templates
- CI/CD
- 公共模块不敢轻易迭代
- 现象:A、B 都依赖 C,某个 B 开发者更新的 C 的代码,B + C 是可以正常工作,但 A + C 可能工作异常了
- 解决办法:理论上需要检查一遍所有可能影响到的模块,检查方式是跑单元测试、编译,但分属不同仓库的时候,这个事情做起来就比较麻烦(我们团队很好的将这个矛盾转移给了 QA 团队)
- 代码复用很麻烦
- 如果 A 的里面一部分代码需要给 B 使用,那么就需要把这部分代码拆分出来,新建一个 C 的仓库,然后再往 npm 发布一个版本(或 submodules)
- 操作步骤比较繁琐,而且很多时候并不需要发布 npm 版本,因为可能是临时的
- 三方依赖版本可能不一致(同一个团队,我们还是尽量希望一致的)
- 实施代码标准化是一项挑战
- 导致代码评审困难,因为缺失上下文
转向 monorepo 的最大好处是我们没有放弃微服务架构的任何优势,这是另一个话题啦。
monorepo
于是乎,社区针对这些问题,就想出了一个 monorepo 的解决方案。简单来说,monorepo 就是 all in one 的意思。
社区对于 monorepo 的使用
- Babel, Jest, and Create React App adopt Monorepo using Lerna 采用 lerna 使用 monorepo
- React 同样使用一个单一的 repo 管理多个 packages,虽然没有采用 lerna
monorepo 的优势
- 单个配置共享:项目相关的配置,比如 lint、test、build、environments、tsconfig 等(工程统一标准化)
- 统一的地方处理 issue、merge request
- 代码重构便捷:毕竟都在同一个 repo 里,解决了公共模块不敢轻易迭代的问题
- 代码复用便捷
- 所有的项目代码都集中于一个代码仓库,我们将很容易抽离出各个项目共用的业务组件或工具,如果有些代码需要复用,直接新增一个平级的 shared 目录,把代码迁移过去,然后修改 a、b、c 相关的逻辑,直接依赖 shared 这个模块
- 愿景:packages 下面的模块越来越多,功能越来越独立。业务就是组合这些模块搭建起来
- 公共三方依赖版本保持一致(共同依赖可以提取至 root,版本控制更加容易,依赖管理会变的方便)
当然了,有优势就有劣势
- 单个 repo 的体积变得很大
- 权限管理的粒度会比较大
- CI 测试运行时间也会变长
monorepo core
搜索引擎搜索 monorepo 相关的实践,都必然会提到 yarn workspaces 和 lerna,为什么需要这两个东西呢,它们一定为解决某个环节中的痛点而生。因为如果只是简单看 monorepo 的概念而言,它只是代码的一种组织方式,不引入新的概念也是完全可以落地的。
我们从只使用 npm 的角度出发,我们应该怎么做呢。我们也着照猫画虎创建一个 packages 文件夹。新建 utils 和 ui package,并通过 npm init 进行初始化。然后 root package 中加入 jest 依赖,ui package 加入 axios 依赖,utils 中加入 lodash 依赖。直接根目录下运行 npm install 进行依赖安装。
最终结果为:仅仅安装 jest,lodash 和 axios 并没有被安装,如果 package 的依赖需要被安装,则需要手动 cd 进入特定目录,进行依赖的安装,也就是说 npm install 只认了同级别目录下的 package.json 文件。
Yarn
很明显这很繁琐,这时候需要 workspaces 来帮助我们了,开启 workspaces 的很简单。直接在 root package.json 下添加 workspaces 字段指定为具体目录即可。
{
"private": "true", // required
"workspaces": [
"packages/*"
]
}
然后指定如下命令,注意这里是 yarn,而不是 npm(使用 npm 的话需要升级到 npm7)
yarn install
最终的结果为:yarn 把 root 以及 packages 下声明的依赖全部安装到了 root node_modules 下
现在 utils 包也需要依赖 axios,但是一个比较旧的版本,因此这里把 axios 加入到 utils/package.json 中,这时候再次执行 yarn install。
依赖安装结果为
- utils 中声明的 axios 依赖提升到了 root 级别
- ui 中有自己的 axios 包
总结一下 yarn 在依赖安装时帮助了我们什么
- yarn 会尽量把依赖拍平装在根目录下,减少重复下载。存在版本不同情况的时候会把使用最多的版本安装在根目录下,其它的就装在各自目录里
- 带来的问题:比如多个 package 都依赖了 React,但是它们版本并不都相同。此时 node_modules 里可能就会存在这种情况:根目录下存在这个 React 的一个版本,包的目录中又存在另一个依赖的版本。依赖拍平的解决方案带来了不同版本依赖冲突的问题。因为 node 寻找包的时候都是从最近目录开始寻找的,此时在开发的过程中可能就会出现多个 React 实例的问题。遇到这种情况的时候,我们就得用 resolutions 去解决问题。resolutions 用于指定使用哪个版本。出现多个版本的问题,通常是因为安装依赖的依赖造成的多版本问题。这种依赖的依赖术语称之为「幽灵依赖」
经实践,yarn resolutions 在 monorepo 项目中,只有在 root package.json 中才生效。
依赖安装的问题解决了后,package 一定是会进行互相引用的,因为拆分 package 的首要目的就是为了要复用。这就要谈到 yarn 做的第二件事,就是软链(link),自己查看根目录下的 node_modules,你会发现你声明的 packages 内容,比如我的
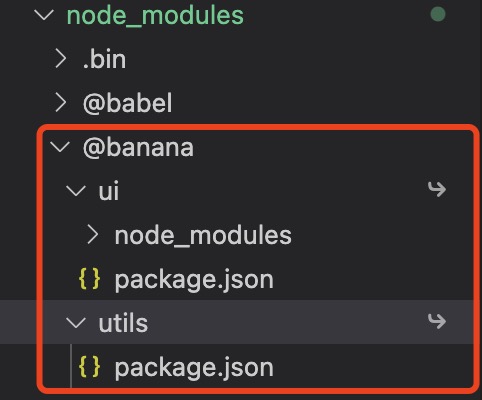
总结一下 yarn 在 link 帮助我们做了什么
- yarn 在安装依赖的时候会帮助我们将各个 package 软链到根目录中,这样每个 package 就能找到另外的 package 以及依赖了
- 新问题:因为各个 package 都能访问到拍平在根目录中的依赖了,因此此时其实我们无需在 package.json 中声明 dependencies 就能使用别人的依赖了。这种情况很可能会造成我们最终忘了加上 dependencies,一旦部署上线项目就运行不起来了。这个问题可以通过 eslint 规则进行解决
进行到这里,好像我的问题已经被解决了
- 针对想要复用的模块,我们可以新建一个 package 进行代码编写
- 由于 yarn 会帮我们进行 link,则此时需要使用该 package 时,直接引用即可
注意:包名指的是 package.json 下的 name 字段,而不是文件夹名。
yarn 还支持什么
- yarn workspace <workspace_name>:可以使用命令行在每个 package 中运行相同的 npm scripts
- yarn.lock:所有 packages 的依赖版本管理,而不是每个 package 中都创建 lock 文件
Yarn 工作空间使得每个 package 可以共享 root 目录的依赖,这对于 devDependencies 来说非常有用,比如 TypeScript、ESLint、Jest 等,它不需要在每个 package.json 中进行声明,降低了在每个包目录中管理这些NPM包的成本
其实仔细思考一番,你会发现问题好像解决了,但又好像没解决。你思考这样一种情况
- 你需要迭代一个 common package 包,但你引入了破坏性更新,这个包同时被 A 和 B 两个包用到,如果 A 和 B 都是由你项目组进行维护,那很好解决,你直接进行兼容更改即可
- 而组织架构复杂后,通常情况你是 A 组,你需要这次更新,但 B 可以不需要,这时候你去修改 B 组代码并不合适,你去要求 B 组去改,那只会更不合适,毕竟他们有手头的事情
那这个问题要怎么解决呢。其实这种关系就构成了一个小型的社区开源,开源项目通常是采用版本的方式,版本号会有严格的管理,比如是大版本还是小版本,针对更新内容出一份详尽的 CHANGELOG,开发者需要更新时,自行根据文档进行更近,当然,做到好的开发项目,甚至会提供工具帮助一键自动修改。
这时候我们就要涉及到版本管理问题
介绍版本管理之前,先了解一下 yarn 提供的版本控制符,workspace range(workspace:)
- 有些情况,你不想使用远程仓库包,即使版本并不匹配。比如你的项目并不准备发布,但是你想使用工作空间更好的间隔代码
- 当你使用 workspace 时,yarn 将拒绝解析到本地工作空间之外的任何东西,有两个特性
- 如果是 semver 范围,它将选择与指定版本匹配的工作区
- 如果是项目相对路径,它将选择与此路径匹配的工作区(实验性的),推荐直接使用
workspace:*
Lerna
Lerna 介绍
- Lerna 是 babel 维护自己的 monorepo,并开源出的一个项目
- Lerna and Yarn:使用 Lerna 发布,使用 yarn workspaces 管理包的依赖
公共依赖提升好处
- 所有包使用相同的依赖版本
- 保持根依赖实时更新,使用自动化工具如 Snyk
- 减少依赖安装时间
- 更少的存储
注意:被 npm scripts 使用二进制可执行文件,仍然需要在每个包中单独安装,如 cross-env
Lerna 的出现就是为了解决构建以及发布问题的工具,我们先进行初始化
lerna init # 在项目根目录下执行该命令,初始化一个 lerna 项目,会创建 package.json、lerna.json、packages 文件夹
命令执行完后生成的默认 lerna.json 如下
{
"packages": [
"packages/*"
],
"version": "0.0.0"
}
接下来直接执行第一常用的命令
lerna bootstrap
执行后结果如下
- 为每个 package 安装外部依赖
- 为互相依赖的 package 建立 symlink
其实 bootstrap 默认还做了一些重要的事就是
- 对所有的 package 执行 npm prepublish(如果有的话),这是为了解决 package 需要执行一次打包才可用的问题
- 对所有的 package 执行 npm prepare
但需要注意的时,root package 声明的依赖(jest)并没有安装。对了 bootstrap 还支持很多参数,其中一个就是 --hoist 用于控制是否需要进行依赖的提升。试试看
lerna bootstrap --hoist
神奇的事发生了,使用了 hoist 参数后
- 依赖被提升到 root 级别,如果存在多个不同版本,处理规则和 yarn 类似
- root package 声明的依赖也被安装了
这不由的让我 hoist 做了什么事情感到好奇,具体见:hoist,但并没有提到 root package 依赖的问题,姑且认为这是它实现提升带来的副作用吧。
咋一看 lerna 把 yarn workspaces 的工作给做了,但 lerna 提供对于开启 workspaces 的控制,开启方式如下(package.json 中对于 workspaces 的配置依旧需要)
"npmClient": "npm",
"useWorkspaces": true
这样依赖 yarn 的能力就被托管给了 lerna,lerna 即使不开启 hoist 参数也会实现依赖提升,那开启 hoist 和使用 workspaces 有什么区别呢,大致看了一下,没有发现太多区别,目前发现的
- hoist 提取公共的依赖到 root node_modules 中,其余依赖安装到 package/node_modules 中,可执行文件必须安装在 package/node_modules 中,workspaces 所有依赖全部在根目录的 node_modules,除了可执行文件
- 网上有说法是:lerna 提供了一个 --hoist 参数将子项目的依赖包提升到最顶层的方式,但这种方式会有一个问题,不同的版本号只会保留使用最多的版本,当项目中有些功能需要依赖老版本时,就会出现问题。但实测没有这个问题
- 如果你没使用 yarn,当你 clone 项目时,你必须使用 lerna bootstrap 命令,但如果你使用了 yarn,则使用 yarn install 同样可以
注意:若开启了 workspace 功能,则 lerna 会将 package.json 中 workspaces 中所设置的项目路径作为 lerna packages 的路径,而不会使用 lerna.json 中的 packages 值。
接下来执行第二常用的命令
lerna publish
lerna publish 流程
- 找出上次发布后有变更的包
- 生成对应的版本号
- 更新对应包 package.json 中的版本号
- 在 Git 中打入对应标签
- 发布到 npm
如果中途包发布失败,运行 lerna publish 的时候,因为 tag 已经打上去了,所以不会再重新发布包到 npm
- 运行 lerna publish from-git,会把当前标签中涉及的 npm 包再发布一次,不会再更新 package.json,只是执行 npm publish
- 运行 lerna publish from-package,会把当前所有本地包中的 package.json 和远端 npm 比对,如果是 npm 上不存在的包版本,都执行一次 npm publish
lerna 版本管理模式
- fixed:任何包中的重大更改都会导致所有包都有一个新的主版本。
- independent:每个 package 的版本都是独立的
版本号变更如果采用 fix 模式,publish 流程会有些许差别
- 找出上次发布后有变更的包
- 根据当前 lerna.json 中的版本生成新的版本
- 更新所有包 package.json 中的版本号
- 更新 lerna.json 中的版本号
- 在 Git 中打入对应标签
- 发布所有包到 npm
由于我自定义的包名含有前缀,发布时提示 E402 You must sign up for private packages。需要在各自包 package 中添加相关配置
{
"publishConfig": {
"access": "public"
},
}
添加后继续 publish,此时提示 E403 Forbidden,但并没有更详尽的提示,测试了很多次发现是包名的问题,将 @banana/ui 改成 try-banana-ui 即发布成功了。吐了,找了一下午才找到原因,因为我发现把 @banana 改成 @banana2 后,报错变成了 404,我发现 npm 中有一个 Organizations 概念,于是乎新建 @banana2,再次 publish 即成功,至于 banana 报错 403 应该是被人用了,但没有发布什么包,好坑,导致我以为没有被用
lerna 通用参数
- --concurrency
:参数可以使 Lerna 利用计算机上的多个核心,并发运行,从而提升构建速度;默认值为 cpu 的核心数。 - --scope '@mono/{pkg1,pkg2}':--scope 参数可以指定 Lerna 命令的运行环境,通过使用该参数,Lerna 将不再是一把梭的在所有仓库中执行命令,而是可以精准地在我们所指定的仓库中执行命令,并且还支持示例中的模版语法;
- --stream:该参数可使我们查看 Lerna 运行时的命令执行信息;
lerna 其他命令
- lerna updated:检查哪些包有更新
- lerna import path/to/existing-repository:从外部导入一个已存在的包,包括 git 历史,该命令仅支持导入本地项目,并且不支持导入项目的分支和标签
- lerna clean:移除所有 packages 的 node_modules
- lerna diff:和上一次版本做比较
- lerna run:在所有子项目中执行 npm script 脚本,并且,它会非常智能的识别依赖关系,并从根依赖开始执行命令
- lerna exec:像 lerna run 一样,会按照依赖顺序执行命令,不同的是,它可以执行任何命令,例如 shell 脚本
- lerna create package_name:新增 package
- lerna add:将本地或远程的包作为依赖添加至当前的 monorepo 仓库中,Lerna 可以识别并追踪包之间的依赖关系
- lerna list:列出所有的 packages
- lerna info:相关软件的版本和位置信息
- lerna link:将本地相互依赖的 package 相互连接. –force-local 无论本地 package 是否满足版本需求,都链接本地的
bootstrap & publish
下面重点看看 bootstrap 和 publish 支持的常用参数
bootstrap 命令:启动指定的 packages
- ignore:忽略哪些 package 的启动
- scope:限定启动哪些 package
- npmClientArgs:透传 npm 支持的参数,比如
--no-package-lock - hoist:是否开启依赖提升
- ignore-prepublish:prepublish 生命将要过期,因此该参数将来会被移除
- ignore-scripts:忽略所有 lifecycle scripts 执行
- force-local:无论版本范围是否匹配,强制本地同级链接
- 如果 lerna1 依赖 lerna2,且版本刚好为本地版本,那么会在 node_modules 中链接本地项目,如果版本不满足,需按正常依赖安装
publish 命令:发布代码有变动的 package
- 前提:在使用 Lerna 前使用 git commit 命令提交代码,好让 Lerna 有一个 baseline
- 原则:不会发布 private 为 true 的包
- ignoreChanges:忽略哪些文件的更新,比如 md 文件
- ignore-scripts
- ignore-prepublish
- message:当版本发布完成后的自定义消息
- registry:设置自定义 npm 仓库,比如你要发布到内网
- no-push:不会自动将修改提交到仓库
- conventional-commits:生成 CHANGELOG
总结
Lerna 无感知的解决了你很多痛点
- 增量构建 & 测试
- 因为所有包都存在一个仓库中了,如果每次执行 CI 的时候把所有包都构建一遍,则会非常浪费时间
- 手动追踪依赖关系非常麻烦:存在包与包之间有依赖的场景时,需要寻找出各个包之间的依赖关系,然后根据这个关系去构建。比如说 A 包依赖了 D 包,当我们在构建 A 包之前得先去构建 D 包才成
- 通过 lerna 执行命令,本身就会去进行拓扑排序,所以包之间存在依赖时的构建问题也就被解决了
- 部署
- 部署单个 package,依赖关系会自动通过拓扑排序解决
- package 部署时版本自动计算和更新
Comparison
npm、yarn 以及 lerna 的意义和区别就很清晰了,依次而言是一种能力的增强,在各自的环节进行发力。
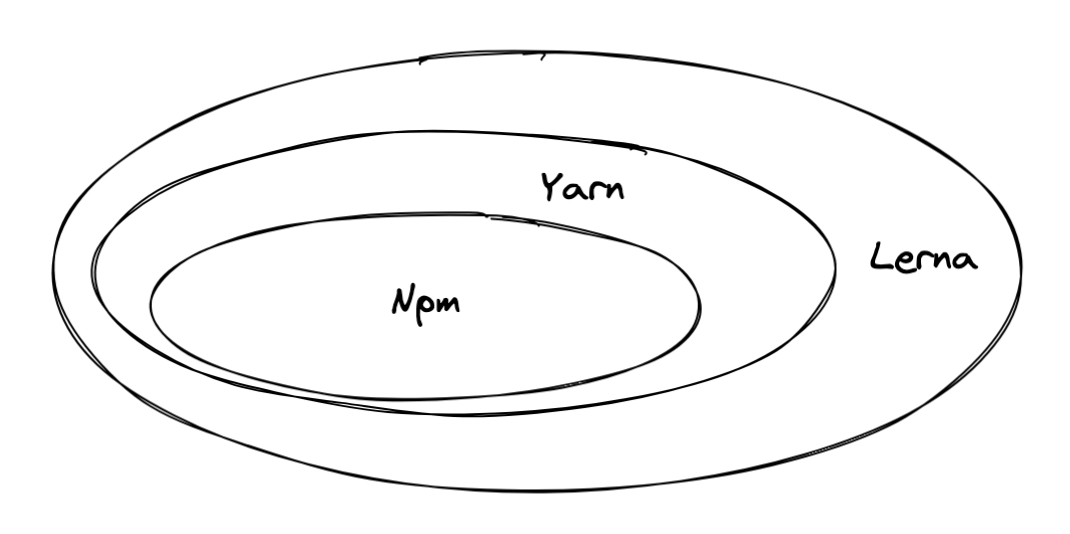
扮演的具体角色
- Npm:负责包安装
- Yarn:负责依赖提升、依赖优化以及 package link
- Lerna:负责构建、测试、发包
- 自动提交和版本号修改
- 交互式commit message
- 自动生成日志
- ……
monorepo around
有了 package 后,其实还有很多同样重要的工作值得去做
- 文档管理:package 要想真正在团队间得到复用,就必须要相应的文档,不然很难落地
- ui:可以采用 storybook 生成在线文档
- module:可以采用 jsdoc 生成文档说明
- Verdaccio:npm 包本地发布
- commitlint or commitizen:检查提交的 commit 信息,它强制约束我们的 commit 信息必须在开头附加指定类型,用于标示本次提交的大致意图,支持的类型关键字有 feat、chore、fix、refactor、style
- 合并配置
- TypeScript、ESLint、Jest、Babel、Prettier、StyleLint、editorconfig、Rollup
- .gitattributes、.gitignore 等
- 统一命令脚本 scripty
- 允许您将脚本命令定义在文件中,并在 package.json 文件中直接通过文件名来引用
- 子项目间复用脚本命令
- 像写代码一样编写脚本命令,无论它有多复杂,而在调用时,像调用函数一样调用
- lerna-changelog 自动生成 CHANGELOG
由于会统一命令脚本,为 npm-scripts 定义命名规则是管理多个包的良好实践。
- build
- start
- clean
- lint
- test
- test:ci (a test script for CI environment)
- prerelease (run scripts that have to run before publishing a package)
结构参考
看看 jest、babel、cra 以及 ant-design 是如何组织的
# jest
├── docs
├── examples
├── packages
├── jest-core
├── package.json # no script
├── tsconfig.json # extends root tsconfig.json
├── scripts # node 执行脚本,统一 submodule 的脚本执行
├── .editorconfig
├── .eslintignore
├── .prettierignore
├── babel.config.js
├── jest.config.ci.js
├── jest.config.js
├── lerna.json
├── package.json
├── build script
├── lint script
├── test script
├── watch script
├── tsconfig.json
# babel
├── docs
├── packages
├── babel-parser
├── typings
├── package.json
├── tsconfig.json # extends root tsconfig.base.json
├── scripts
├── .editorconfig
├── .eslintignore
├── .eslintrc.cjs
├── .gitattributes
├── .gitignore
├── .prettierignore
├── .prettierrc
├── babel.config.js
├── jest.config.js
├── package.json
├── tsconfig.base.json # 基本的 ts 开关配置
├── tsconfig.json # 手动配置 include 所有 package 下的 ts 文件,以及对应的 paths 别名,unbelievable
# create-react-app
├── docusaurus # 类比 docs,应用了 facebook 推出的静态文档站点
├── packages
├── react-script
├── package.json
├── tasks # 类比 scripts
├── .eslintignore
├── .eslintrc.json
├── .gitattributes
├── .gitignore
├── .prettierrc
├── lerna.json
├── package.json
├── changelog script # 依赖 lerna-changelog
# ant-design
├── .husky
├── components
├── docs
├── scripts
├── tests
├── typings
├── .editorconfig
├── .eslintignore
├── .eslintrc.js
├── .gitignore
├── .prettierignore
├── .prettierrc
├── package.json
├── files # dist、lib、es
├── tsconfig.json
├── webpack.config.js
没那么重要的东西
看到一句话角色很喜欢:代码复用归根到底是一个关于人际沟通的文化问题,最重要的是不忘模块化这一初心
纯文件方式引用
曾经有个错误的想法,就是针对 package 不引入额外的打包机制,而是直接放到 web 项目里去一同打包,比如 CRA 创建的项目中。结论就是可以是可以,但是很麻烦,且不通用。这里只是记录下步骤和坑
- 禁用 ModuleScopePlugin,将 webpack 的工作范围不在只是 src 目录
- 扩展 typescript 的 paths 字段,进行别名扩展
- 扩展 typescript 的 include 字段
- 修改 webpack 配置,将对应的纯文件目录加入 babelInclude 列表
- 修改 webpack 配置,增加对应纯文件目录的 alias 配置
- TypeScript 设置别名导致顶级别名下,必须写完 index,否则提示找不到
- 这是由于 paths 的语法导致的,因为别名使用的是
@config/*导致匹配不到@config - 但这个好坑,真要解决的话,好像只能写两个,也就是再写一个
@config专门用于匹配它
- 这是由于 paths 的语法导致的,因为别名使用的是