今天看到一篇讲解引擎和线程的文章,解开了自己关于这一块的疑惑,加深了JavaScript基础,做点小笔记。
进程和线程
- 单个CPU一次只能运行一个任务(进程),其他进程处于非运行状态。
- 一个进程可以包括多个线程。
- 个进程的内存空间是共享的,每个线程都可以使用这些共享内存。
- 某些内存区域,一次只能给一个线程使用,因此一个线程使用这些共享内存时,其他线程必须等它结束,才能使用这一块内存。"互斥锁"(Mutual exclusion,缩写 Mutex),防止多个线程同时读写某一块内存区域。
- 某些内存区域,只能供给固定数目的线程使用。"信号量"(Semaphore),用来保证多个线程不会互相冲突。
操作系统的设计,因此可以归结为三点:
- 以多进程形式,允许多个任务同时运行;
- 以多线程形式,允许单个任务分成不同的部分运行;
- 提供协调机制,一方面防止进程之间和线程之间产生冲突,另一方面允许进程之间和线程之间共享资源。
运行机制
单线程
也许你会问,为什么JavaScript语言要设计成单线程呢?最大的原因是简单。
作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。
所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
任务队列
单线程就意味着,所有任务需要排队,前一个任务结束,才会执行后一个任务。如果前一个任务耗时很长,后一个任务就不得不一直等着。
有个问题值得我们注意的是,如果排队时因为计算量大,那我们无话可说,但现实就是很多时候CPU是闲着的,因为IO设备很慢(Ajax操作),不得不等结果出来再往下执行。
JavaScript语言的设计者意识到,这时主线程完全可以不管IO设备,挂起处于等待中的任务,先运行排在后面的任务。等到IO设备返回了结果,再回过头,把挂起的任务继续执行下去。
所有任务可以分成两种,一种是同步任务(synchronous),另一种是异步任务(asynchronous)。同步任务指的是,在主线程上排队执行的任务,只有前一个任务执行完毕,才能执行后一个任务;异步任务指的是,不进入主线程、而进入"任务队列"(task queue)的任务,只有"任务队列"通知主线程,某个异步任务可以执行了,该任务才会进入主线程执行。
异步执行的运行机制如下:
- 所有同步任务都在主线程上执行,形成一个执行栈
- 主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
- 一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
- 主线程不断重复上面的第三步。
"任务队列"是一个事件的队列(也可以理解成消息的队列),IO设备完成一项任务,就在"任务队列"中添加一个事件,表示相关的异步任务可以进入"执行栈"了。主线程读取"任务队列",就是读取里面有哪些事件。
"任务队列"中的事件,除了IO设备的事件以外,还包括一些用户产生的事件(比如鼠标点击、页面滚动等等)。只要指定过回调函数,这些事件发生时就会进入"任务队列",等待主线程读取。
所谓"回调函数"(callback),就是那些会被主线程挂起来的代码。异步任务必须指定回调函数,当主线程开始执行异步任务,就是执行对应的回调函数。
Event Loop
主线程从"任务队列"中读取事件,这个过程是循环不断的,所以整个的这种运行机制又称为Event Loop(事件循环)。
事件轮询:事件轮询的工作是监听调用堆栈,并确定调用堆栈是否为空。如果调用堆栈是空的,它将检查消息队列,看看是否有任何挂起的回调等待执行。
ES6引入了任务队列的概念,任务队列是 JavaScript 中的 promise 所使用的。消息队列和任务队列的区别在于,任务队列的优先级高于消息队列,这意味着任务队列中的promise 作业将在消息队列中的回调之前执行
JavaScript 引擎的一个流行示例是 Google 的V8引擎。例如,在 Chrome 和 Node.js 中使用V8引擎,V8引擎由两个主要部件组成:
- Memory Heap(内存堆) — 内存分配地址的地方
- Call Stack(调用堆栈) — 代码执行的地方
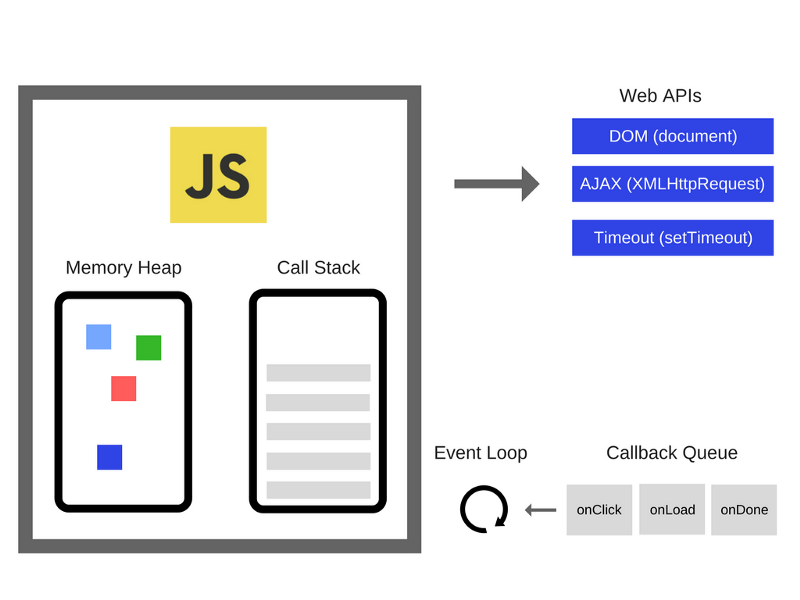
JavaScript是一种单线程编程语言,这意味着它只有一个调用堆栈。因此,它一次只能做一件事。
调用栈是一种数据结构,它记录了我们在程序中的位置。如果我们运行到一个函数,它就会将其放置到栈顶,当从这个函数返回的时候,就会将这个函数从栈顶弹出,这就是调用栈做的事情。
正常任务与微任务
正常任务(task)与微任务(microtask)。它们的区别在于,“正常任务”在下一轮Event Loop执行,“微任务”在本轮Event Loop的所有任务结束后执行。
正常任务包括以下情况:
- setTimeout / setInterval / setImmediate
- MessageChannel
- postMessage
- ajax
- I/O
- 事件回调函数
微任务目前主要是
- process.nextTick
- MutationObsever
- Promise
执行顺序简单如下:
for (macroTask of macroTaskQueue) {
// 1. Handle current MACRO-TASK
handleMacroTask();
// 2. Handle all MICRO-TASK
for (microTask of microTaskQueue) {
handleMicroTask(microTask);
}
}
线程机制
首先我们通过页面卡顿的原因引入两个常见的线程:UI 渲染线程与 JavaScript 引擎线程。
由于 JavaScript 是可操纵 DOM 的,如果在修改这些元素属性同时渲染界面(即 JavaScript 线程和 UI 线程同时运行),那么渲染线程前后获得的元素数据就可能不一致了。为了防止渲染出现不可预期的结果,浏览器设置 UI 渲染线程与 JavaScript 引擎线程为互斥的关系,当 JavaScript 引擎线程执行时 UI 渲染线程会被挂起,UI 更新会被保存在一个队列中等到 JavaScript 引擎线程空闲时立即被执行。
假设一个 JavaScript 代码执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染出现“加载阻塞”的现象。当然,针对 DOM 的大量操作也会造成页面出现卡顿现象,毕竟我们经常说:DOM 天生就很慢。
浏览器中的那些线程
前端某些任务是非常耗时的,比如网络请求,定时器和事件监听,如果让他们和别的任务一样,都老老实实的排队等待执行的话,执行效率会非常的低,甚至导致页面的假死。所以浏览器是多线程的,除了之前介绍的两个互斥的呈现引擎和 JavaScript 解释器,浏览器一般还会实现这几个线程:浏览器事件触发线程,定时触发器线程以及异步 HTTP 请求线程。
- 浏览器事件触发线程:当一个事件被触发时该线程会把事件添加到待处理队列的队尾,等待 JavaScript 引擎的处理。这些事件可以是当前执行的代码块如定时任务、也可来自浏览器内核的其他线程如鼠标点击、AJAX 异步请求等,但由于 JavaScript 的单线程关系所有这些事件都得排队等待 JavaScript 引擎处理;
- 定时触发器线程:浏览器定时计数器并不是由 JavaScript 引擎计数的, 因为 JavaScript 引擎是单线程的, 如果处于阻塞线程状态就会影响记计时的准确, 因此通过单独线程来计时并触发定时是更为合理的方案
- 异步 HTTP 请求线程:在 XMLHttpRequest 在连接后是通过浏览器新开一个线程请求, 将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件放到 JavaScript 引擎的处理队列中等待处理;
定时器
面试的时候,被问道setTimeout第二个参数设置0的目的是什么?当时还真是有点语塞啊,现在看来有了更深的理解。
基本功能和使用我就不介绍了。了解一下哪些不知道的:
- 第一个参数可以是字符串,引擎内部使用eval函数,将字符串转为代码,但一方面eval函数有安全顾虑,另一方面为了便于JavaScript引擎优化代码,setTimeout方法一般总是采用函数名的形式。
- 参数问题,除了前两个参数,setTimeout还允许添加更多的参数。它们将被传入推迟执行的函数(回调函数),IE 9.0及以下版本,只允许setTimeout有两个参数,不支持更多的参数。如果需要传参呢,有三种解决办法
- 使用匿名函数
- 使用bind
- 自定义setTimeout,使用apply方法将参数输入回调函数
- this问题,如果被setTimeout推迟执行的回调函数是某个对象的方法,那么该方法中的this关键字将指向全局环境,而不是定义时所在的那个对象。解决办法
- 一种解决方法是将object.func放在函数中执行。
- 使用bind方法,将func绑定到object上
HTML 5标准规定,setTimeout的最短时间间隔是4毫秒。为了节电,对于那些不处于当前窗口的页面,浏览器会将时间间隔扩大到1000毫秒。另外,如果笔记本电脑处于电池供电状态,Chrome和IE 9以上的版本,会将时间间隔切换到系统定时器,大约是15.6毫秒。
setInterval指定的是“开始执行”之间的间隔,并不考虑每次任务执行本身所消耗的时间。因此实际上,两次执行之间的间隔会小于指定的时间。比如,setInterval指定每100ms执行一次,每次执行需要5ms,那么第一次执行结束后95毫秒,第二次执行就会开始。如果某次执行耗时特别长,比如需要105毫秒,那么它结束后,下一次执行就会立即开始。setInterval不会产生累积效应。
为了确保两次执行之间有固定的间隔,可以不用setInterval,而是每次执行结束后,使用setTimeout指定下一次执行的具体时间。
HTML 5标准规定,setInterval的最短间隔时间是10毫秒,也就是说,小于10毫秒的时间间隔会被调整到10毫秒。
setTimeout和setInterval返回的整数值是连续的,也就是说,第二个setTimeout方法返回的整数值,将比第一个的整数值大1。利用这一点,可以写一个函数,取消当前所有的setTimeout。
clearTimeout(),clearInterval()典型的使用场景:防抖
现实中,最好不要设置太多个setTimeout和setInterval,它们耗费CPU。比较理想的做法是,将要推迟执行的代码都放在一个函数里,然后只对这个函数使用setTimeout或setInterval。
运行机制
setTimeout和setInterval的运行机制是,将指定的代码移出本次执行,等到下一轮 Event Loop 时,再检查是否到了指定时间。如果到了,就执行对应的代码;如果不到,就等到再下一轮 Event Loop 时重新判断。
这意味着,setTimeout和setInterval指定的代码,必须等到本轮 Event Loop 的所有任务都执行完,才会开始执行。由于前面的任务到底需要多少时间执行完,是不确定的,所以没有办法保证,setTimeout和setInterval指定的任务,一定会按照预定时间执行。
setTimeout(f, 0)
从上面我们已经知道,必须要等到当前脚本的同步任务和“任务队列”中已有的事件,全部处理完以后,才会执行setTimeout指定的任务。也就是说,setTimeout的真正作用是,在“消息队列”的现有消息的后面再添加一个消息,规定在指定时间执行某段代码。setTimeout添加的事件,会在下一次Event Loop执行。
setTimeout(f, 0)将第二个参数设为0,作用是让f在现有的任务(脚本的同步任务和“消息队列”指定的任务)一结束就立刻执行。也就是说,setTimeout(f, 0)的作用是,尽可能早地执行指定的任务。而并不是会立刻就执行这个任务。
即使消息队列是空的,0毫秒实际上也是达不到的。根据HTML 5标准,setTimeout推迟执行的时间,最少是4毫秒。如果小于这个值,会被自动增加到4。这是为了防止多个setTimeout(f, 0)语句连续执行,造成性能问题。
另一方面,浏览器内部使用32位带符号的整数,来储存推迟执行的时间。这意味着setTimeout最多只能推迟执行2147483647毫秒(24.8天),超过这个时间会发生溢出,导致回调函数将在当前任务队列结束后立即执行,即等同于setTimeout(f, 0)的效果。
那么设置为延迟时间为0有哪些具体的应用场景呢?
- 调整事件的顺序:网页开发中,某个事件先发生在子元素,然后冒泡到父元素,即子元素的事件回调函数,会早于父元素的事件回调函数触发。如果,我们先让父元素的事件回调函数先发生,就要用到setTimeout(f, 0)。
- 用户自定义的回调函数,通常在浏览器的默认动作之前触发。比如,用户在输入框输入文本,keypress事件会在浏览器接收文本之前触发。因此,下面的回调函数是达不到目的的。
document.getElementById('input-box').onkeypress = function(event) { this.value = this.value.toUpperCase(); } /* 在用户输入文本后,立即将字符转为大写。但是实际上,它只能将上一个字符转为大写,因为浏览器此时还没接收到文本,所以this.value取不到最新输入的那个字符。只有用setTimeout改写,上面的代码才能发挥作用 */ document.getElementById('my-ok').onkeypress = function() { var self = this; setTimeout(function() { self.value = self.value.toUpperCase(); }, 0); } - 那些计算量大、耗时长的任务,常常会被放到几个小部分,分别放到setTimeout(f,0)里面执行
内存管理
JS会自动收集内存进行释放,历史上有两种管理方式
- 引用计数垃圾收集算法
- 如果没有指向对象的引用,则认为该对象是“垃圾可回收的”
- 当涉及到循环引用时,会有一个限制,算法会认为,由于每个对象至少被引用一次,所以它们都不能被垃圾收集。
- 标记-清除算法
- 垃圾收集器构建一个“根”列表,用于保存引用的全局变量。在JavaScript中,“window”对象是一个可作为根节点的全局变量。
- 算法检查所有根及其子节点,并将它们标记为活动的(这意味着它们不是垃圾)。任何根不能到达的地方都将被标记为垃圾。
- 垃圾收集器释放所有未标记为活动的内存块,并将该内存返回给操作系统。
截至2012年,所有现代浏览器都有标记-清除垃圾收集器。过去几年在JavaScript垃圾收集(分代/增量/并发/并行垃圾收集)领域所做的所有改进都是对该算法(标记-清除)的实现改进
内存泄漏可以定义为:不再被应用程序所需要的内存,出于某种原因,它不会返回到操作系统或空闲内存池中。
四种常见的内存泄漏
- 全局变量
- 被遗忘的定时器和回调
- 闭包
- 脱离DOM的引用